DyNetML: Interchange Format for Rich Social Network Data
This work was supported in part by the Department of Defense, the NSF ITR 1040059 and the Office of Naval Research N00014-02-1-0973, and the National Science Foundation under the IGERT program for training and research in CASOS. Additional support was provided by CASOS - the center for Computational Analysis of Social and Organizational Systems at Carnegie Mellon University. The views and conclusions contained in this document are those of the author and should not be interpreted as representing the official policies, either expressed or implied, of the Department of Defense, the Office of Naval Research, the National Science Foundation, or the U.S. government.
Current version
Last updated: March 27, 2015DyNetML specification in RELAX NG format can be found here
DyNetML examples can be found here:
For information on ORA-PRO
ORA-PRO is offered by Netanomics, visit their website.
Introduction
Current state of the art in social network data representation presents a fairly bleak picture. Each of the analysis and simulation packages uses its own, proprietary and incompatible data format. Some of the file formats do not even have a specification document, making the files unreadable without the software that produced them. Data formats that were designed for interoperability (such as DL) are rarely expressive enough to fully represent the datasets. As a result, most researchers are forced to deal with data interchange in a makeshift fashion, at best increasing the workload and at worst resulting in loss of data integrity. To improve cooperation between researchers and to promote interoperability of software, the community needs to agree on a common data interchange language. In an informal meeting at CASOS 2002, a number of prominent developers and users of social network analysis tools agreed to cooperate in the development of an interchange language and to support it when it is available. This paper proposes an XML-derived language that addresses requirements for expressivity and compatibility. We proceed to outline our vision for the development of social network analysis toolchains which will increase the ability of researchers to share and analyze dataPitfalls of the Existing Tools
As we mentioned above, the current social network data formats have a number of deficiencies:Binary files are very difficult to read if exact specification of the file format is not provided. Significant extra efforts are required to keep compatibility with other tools or between versions of the same tool.
Multiple files used for specification of rich data or saving analysis output present a number of problems. First of all, there is a significant potential for data loss due to misplaced or corrupted files (for example, while sent through email). Secondly, a consistent naming scheme for all files and a file catalogue are required to prevent data loss - an extra burden on the researcher (as these features are not included in the analysis software)
Raw Data files such as binary matrices or edge lists lack the expressiveness required to represent multiple relations between nodes or evolution of social networks over time.
Human-Readable Data in text files or spreadsheets solves the expressivity problem but requires extensive post-processing by hand or with post-processing scripts. However, these programs often represent the weakest link in the software chain (due to hasty design and dependance on outside tools such as Perl or Awk).
Requirements for Data Interchange
In light of the problems outlined above, we proceed to define requirements for a universal data interchange format that would facilitate the task of exchanging rich social network data and improving compatibility of analysis and visualization tools.- The data interchange format shall be contained in human-readable text files that are at the same time easily parsable by computers.
- The data interchange format shall allow an entire dataset, complete with all computed measurements, to be stored in one file
- The data interchange format shall provide maximum expressive power to its users, allowing:
- Typed nodes (types may include "person", "resource", "organization", "knowledge", etc)
- Multiple sets of nodes of the same type (to express multiple units within the company, etc)
- Multiple typed attributes per node
- Typed edges
- Multiple typed attributes per edge
- Multiple graphs (sets of edges) expressed within the same file
- Dynamic network data expressed in a single file
- The data interchange format shall allow developers to extend it in a fashion that will not break existing software
- The data interchange format shall be flexible enough to be used as both input and output of analysis tools.
DyNetML: Rich Social Network Data Interchange Language
Faced with a pressing need for tool interoperability within our laboratory, we have developed DyNetML - an XML derivative language that addresses the above requirements. Figure 1 shows the hierarchical structure of the DyNetML files.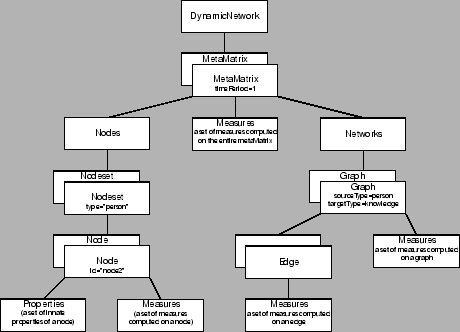
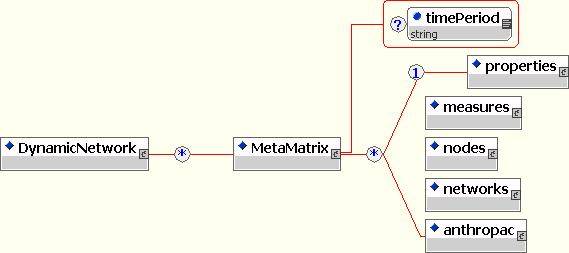
The <DynamicNetwork> element encapsulates all time periods within a dynamic network.
Each time period is represented by a <MetaMatrix> element, which encapsulates network data for a single time period, including multiple matrices and node and properties. Optional ``timePeriod'' attribute identifies the time at which a given metamatrix has been collected.
Optional <measures> element encapsulates a set of MetaMatrix-level measures that have been computed on the given time period.
<measure name=''sampleMeasure'' type=''double'' value=''1''>
Each measure is specified with a unique name, type (double, string, boolean) and value
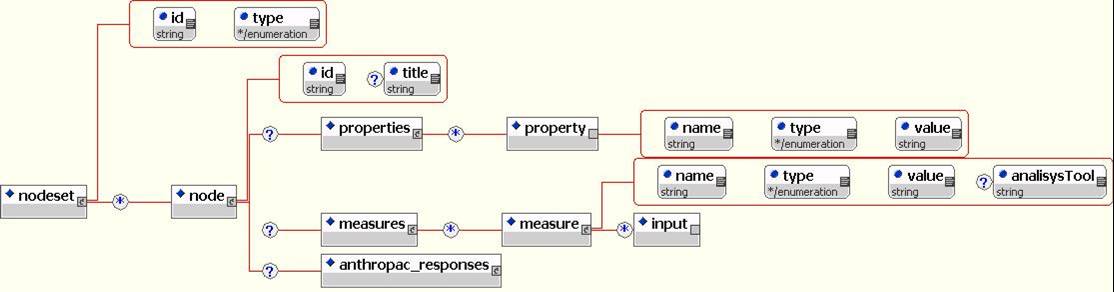
<nodes> element encapsulates all of the nodesets in a given MetaMatrix.
<nodeset id=''nodeset1'' type=''agent''>
A nodeset is a grouping of nodes by type; types include agent, knowledge, resource, task, organization, location. More the one nodeset of the same type can be defined; nodeset ID must be unique.
Each <node> within a <nodeset> has to be supplied with a unique ID and can contain an arbitrary number of innate <properties> or computed <measures>. This allows the data collectors to specify arbitrarily complex data about nodes while separating collected data from results of analysis.
The <networks> element encapsulates network data stored as graph connection lists.
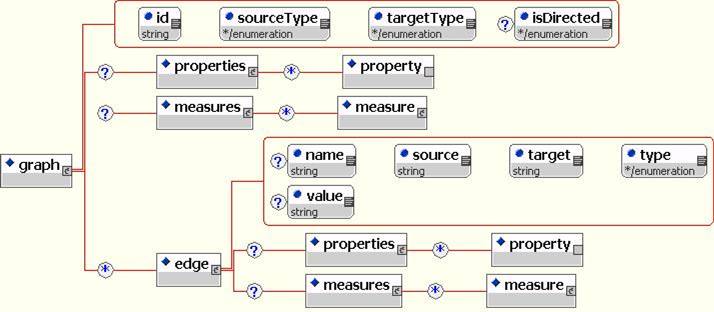
The <graph> nodes are specified with a unique ID and IDs of the source and target nodesets. Each Graph contains a collection of Edge elements whose source and target are nodes previously declared in a Nodeset.
This allows the user to specify an arbitrary number of networks involving the same (e.g friendship and advice networks) or different types of actors (e.g. communication and resource distribution networks).
<edge source=''node1'' target=''node2'' type=''double'' value=''1''>
Edges are represented by specifying the source and target of the edge. Each edge also has a value
and a value type (double, string or boolean).
Each graph and edge can also be followed by a set of innate Properties and computed Measures.
For more information, please refer to the Document Type Definition (DTD) and a sample dataset in the appendix of this paper.
Support of DyNetML DyNetML is currently supported through a C and Java libraries that are a part of the CASOS software suite. Since XML parsers exist for practically all platforms and languages, integration of DyNetML into existing tools can be completed in one day or less. Converters from DyNetML to UCINET (DL), comma-separated values and raw matrices; and from raw matrices to DyNetML, are available from the download section on the top of this document.
Analysis Toolchains: A Vision of the Future
While the research community has developed a number of very powerful data gathering, analysis and visualization tools, the tools rarely operate well with each other. While file import/export options make it possible to use multiple analysis tools within a single project, a lack of automation and scripting features does not allow for batch-processing of data and report generation, thus vastly increasing labour requirements for analysis of complex datasets.In our vision, the future of social network analysis lies in creating a seamless toolchain, enabling researchers to mix and match data gathering, analysis and visualization tools and to create analysis scripts for batch-mode processing of large datasets or for repeating the same analysis on different datasets. Publishing analysis scripts would allow the research community to more easily reproduce and verify experimental or empirical results.
Each of the tools on the toolchain shall:
- Take the accepted data interchange format (such as DyNetML) as input and produce it as output (with the exception of conversion tools)
- Analysis tools shall integrate computational results into the dataset, using accepted measure identifiers
- Each tool that modifies the dataset shall mark its modifications with tool name or ID.
- Each tool shall provide a command-line interface that allows full access to its features via a scripting language
- A C-like scripting language shall be developed for integration of tools within the toolchain. Alternatively, existing scripting languages such as Java, Perl or Python can be used.
- Visual analysis builder tools shall be developed to allow creation of analysis scripts by non-programmers
Conclusion
An integrated toolchain such as the one outlined above can only be created through cooperation of members of the research community through an open-source development process, but the first step is to create a uniform data interchange language. In this paper, we proposed one such language: DyNetML, an XML-derived language for specification of rich social network data.
It is important to note that since DyNetML is intended as a service to the social network analysis and simulation community, comments and requests for revisions are welcome at any time. Once the project has considerable community support, we shall establish a revision process that will respond to the requirements of the community while maintaining backward compatibility with existing software.
About this document ... DyNetML: Interchange Format for Rich Social Network Data
This document was generated using the LaTeX2HTML translator Version 2002 (1.62)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 paper.tex
The translation was initiated by Maksim Tsvetovat on 2003-08-03